Text Summarization with Transformers
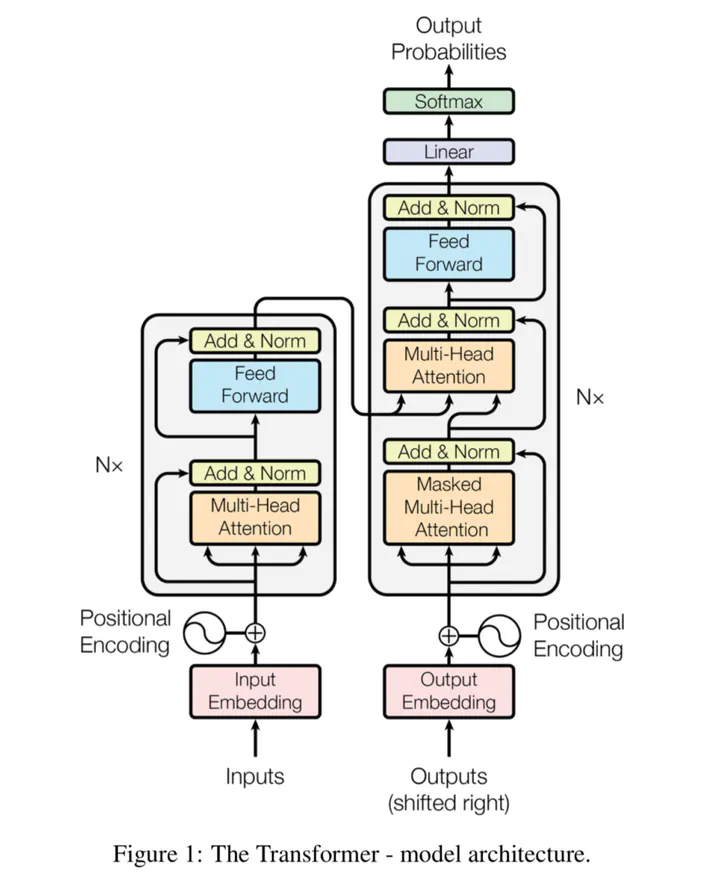 Image credit: Source: Vaswani et al. (2017)
Image credit: Source: Vaswani et al. (2017)Table of Contents
Introduction
Natural Language Processing is one of the key areas where Machine Learning has been very effective. In fact, whereas NLP traditionally required a lot of human intervention, today, this is no longer true. Specifically Deep Learning technology can be used for learning tasks related to language, such as translation, classification, entity recognition or in this case, summarization.
We discuss the following in the article:
- Understand what a Transformer is at a high level.
- See how BERT and GPT can be composed to form the BART Transformer.
- Create a Text Summarization pipeline that really works on all of your English texts!
Machine Learning for Text Summarization
Human beings have limited cognitive capacity for performing certain texts. Today, many people aren’t fond of reading large amounts of text anymore. For this reason, summarizing texts is quite important: when studying for exams, reading self-help books, or simply reading the news, today’s world is becoming so accelerated that time is of the absolute essence.
What is a Transformer?
In Natural Language Processing, the state-of-the-art in Machine Learning today involves a wide variety of Transformer-based models.
A Transformer is a machine learning architecture that combines an encoder with a decoder and jointly learns them, allowing us to convert input sequences (e.g. phrases) into some intermediate format before we convert it back into human-understandable format. They have become the primary choice for ML driven language tasks these days because they can apply self-attention and are parallel in nature. Previous approaches liken RNN, LSTM, couldn’t do this: they either suffered from long-term memory loss or experienced significant compute bottlenecks. Transformers don’t, and in fact, we can train them on datasets with unprecedented scale (Dosovitskiy et al., 2020).
BERT and GPT models
Since the introduction of Transformers by Vaswani et al. (2017), many improvements have been suggested. Two of these improvements are BERT and GPT:
- The Bidirectional Encoder Representations from Transformers (BERT) by Devlin et al. (2018) takes the encoder segment from the classic (or vanilla) Transformer, slightly changes how the inputs are generated (by means of WordPiece rather than learned embeddings) and changes the learning task into a Masked Language Model (MLM) plus Next Sentence Prediction (NSP) rather than training a simple language model. They also follow the argument for pretraining and subsequent fine-tuning: by taking the encoder segment only, pretraining it on massive datasets, BERT can be used as the encoder for subsequent finetuning tasks. In other words, we can easily build on top of BERT and use it as the root for training our own models with significantly smaller language datasets.
- Since BERT utilizes the encoder segment from the vanilla Transformer only, it is really good at understanding natural language, but less good at generating text.
- BERT’s differences ensure that it does not only look at text in a left-to-right fashion, which is common in especially the masked segments of vanilla Transformers. Rather, it is bidirectional, which means that it can both look at text in a left-to-right and right-to-left fashion.
- The Generative Pre-Training GPT model series were invented by OpenAI and take the decoder segment of vanilla Transformers (Radford et al., 2018). It is therefore really good at generating text.
BART = BERT-like encoder and GPT-like decoder
Above, we saw that a pretrained BERT model is really good at understanding language (and hence understanding input text) but less adequate at generating new text. In other words, while it can understand questions really well (see Google, which is utilizing BERT for many search queries these days), it’s not the primary choice for generating the answers.
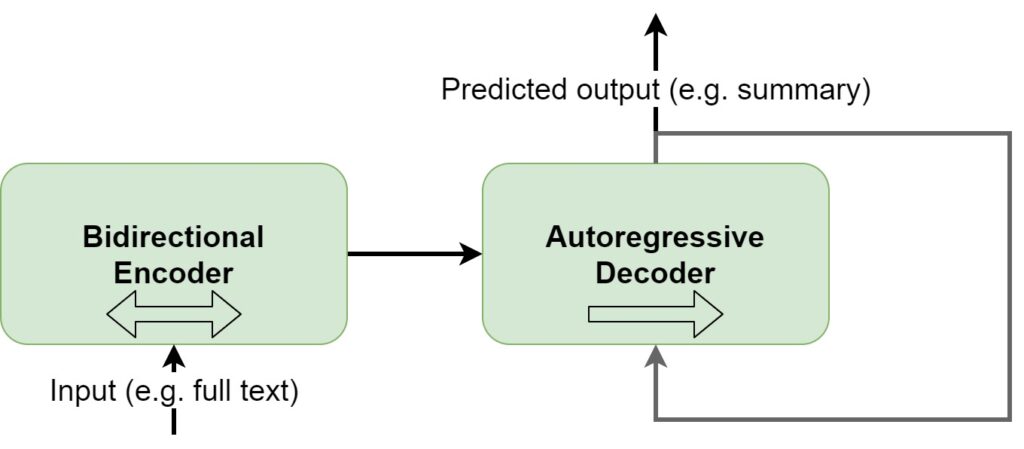
This is where BART comes in, which stands for Bidirectional and Auto-Regressive Transformers (Lewis et al., 2019). It essentially generalizes BERT and GPT based architectures by using the standard Seq2Seq Transformer architecture from Vaswani et al. (2017) while mimicing BERT/GPT functionality and training objectives. For example, pretraining BART involves token masking (like BERT does), token deletion, text infilling, sentence permutation and document rotation. Once the pretrained BART model has finished training, it can be fine-tuned to a more specific task, such as text summarization.
In the schema below, we visualize what BART looks like at a high level. First of all, you can see that input texts are passed through the bidirectional encoder, i.e. the BERT-like encoder. By consequence, texts are looked at from left-to-right and right-to-left, and the subsequent output is used in the autoregressive decoder, which predicts the output based on the encoder input and the output tokens predicted so far. In other words, with BART, we can now both understand the inputs really well and generate new outputs.
That is, we can e.g. finetune a model for a text summarization task.
References
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30, 5998-6008.